在应用中使用celery
项目结构:
1 | proj/__init__.py |
proj/celery.py
1 | from __future__ import absolute_import, unicode_literals |
在这个模块中,创建一个Celery实例。其中:
- broker表示消息中间件
- backend表示结果存储的地方
- include表示worker启动时,要导入的task。只有加入到这里,worker才能找到他们。
proj/tasks.py
1 | from __future__ import absolute_import, unicode_literals |
使用celery命令启动worker。注意:运行启动命令时,需要保证你所在的位置在proj的上层(就是和proj同级的目录下)。
1 | celery -A proj worker --loglevel=info |
当worker启动的时候,你可以看到这些信息: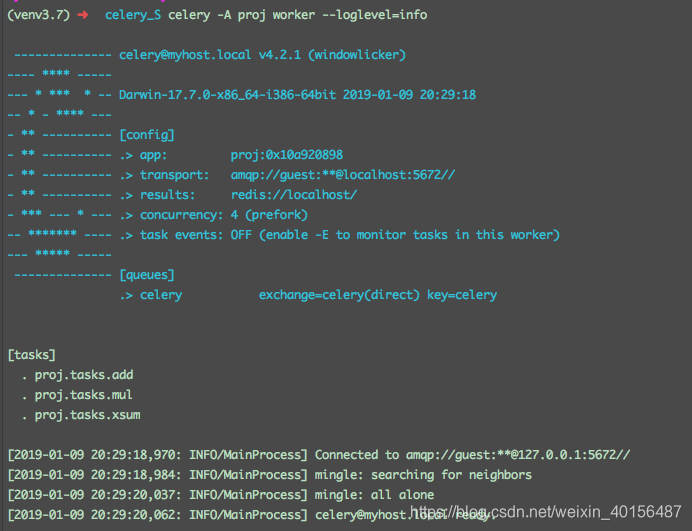
- transport:也就是broker,就是在定义celery实例时的broker参数。或者,我们可以通过
-b命令在运行时指定broker - concurrency:fork出的可以处理task的并发的worker进程数。当这些worker都在忙时,新的任务会等待直到其中一个结束。默认情况下,并发数量时cpu的数量,我们可以通过使用
celery worker -c指定。如果任务主要是IO类型的,可以通过将进程数增加超过cpu数量的两倍,但是这样可能会降低一些性能。celery也支持使用Eventlet, Gevent在单线程中运行 - task events:如果将它打开,celery会监控worker中发生的操作并发送监控消息(事件)。这些可用与一些监控程序,如celery 事件,Flower-实时celery监控。
- queues:worker会从queues里消费任务。worker会被告知能从多个队列消费任务,这被用于将消息路由到指定的worker,从而可以实现优先级排序等问题。
在后台运行celery
在后台,可以利用守护进程执行celery multi命令开启一个或多个worker:
1 | celery multi start w1 -A proj -l info |

也可以重新启动:
1 | celery multi restart w1 -A proj -l info |
停止worker:
1 | celery multi stop w1 -A proj -l info |
stop命令是异步的,因此他不会等待全部worker都执行完才停止。如果想等待所有worker都执行完当前正在执行的任务才停止celery,可以使用stopwait:
1 | celery multi stopwait w1 -A proj -l info |
注意:celery multi不存储有关worker的信息,因此在重新启动时需要使用相同的命令行参数。 停止时,只能使用相同的pidfile和logfile参数。默认情况下,它会在当前目录中创建pid和日志文件,以防止多个worker在彼此之上启动,不过,还是推荐将这些文件放在专用目录中:
1 | sudo mkdir -p /var/run/celery |
使用multi命令可以启动多个worker,并且还有一个强大的命令行语法来为不同的worker指定参数,例如:
1 | celery multi start 10 -A proj -l info -Q:1-3 images,video -Q:4,5 data -Q default -l:4,5 debug |
这行命令的意思是:开启10个worker,其中三个处理images和video队列的任务,两个处理data队列的任务并且日志级别为debug,剩下的worker处理default队列的任务
调用任务
可以使用delay()方法:
1 | >>> add.delay(2, 2) |
这个方法实际上是apply_async ()的另一种快捷方式,它相当于:
1 | >>> add.apply_async((2, 2)) |
在终端中试着调用:
1 | from proj.tasks import add |

而apply_async可以制定一些选项,例如运行时间(倒计时),被发送到的队列等等
1 | >>> add.apply_async((2, 2), queue='lopri', countdown=10) |
在上面的示例中,任务将被发送到名为lopri的队列,任务将在发送消息后最早10秒执行。
另外一种调用方式,就是直接调用__call__(),它会立即反悔结果,并且不发任务:
1 | >>> add(2, 2) |
以上三种方式都叫做celery的”Calling API”
每个任务调用都将被赋予唯一标识符(UUID),这是任务ID(task id)。delay和apply_async方法返回一个AsyncResult实例,该实例可用于跟踪任务执行状态。 但为此你需要启用一个backend,以便状态可以存储在某个地方。默认情况下,不会指定backend,因为不是任意一个backend都适合每一个应用。因此,在选择backend的时候,需要考虑他的优缺点。backend也不适合监控任务。
如果配置了backend,可以这样获取结果:
1 | >>> res = add.delay(2, 2) |
也可以通过id属性查看task id
1 | >>> res.id |
如果task抛出异常,我们是可以获取到异常的,默认情况下,res.get()会自动把异常抛出:
1 | >>> res = add.delay(2) |
这种情况下,会看到:
1 | Traceback (most recent call last): |
官网给出的抛出异常的点是在get之后,但是这里我发现,其实在执行到res = add.delay(2)的时候,就已经抛出异常了:

如果不想抛出异常,可以指定propagate为False:
1 | >>> res.get(propagate=False) |
如果想要查看任务执行的结果,必须在指向结果的对象上查看:
1 | >>> res.failed() |
那么,它是如果知道任务执行成功或失败的呢?他会查看任务的状态:
1 | >>> res.state |
任务只能处于单个状态,但可以从多个状态转化过来。 典型任务的执行状态阶段可以是:
1 | PENDING -> STARTED -> SUCCESS |
STARTED状态是一种特殊状态,仅在启用task_track_started设置或者为任务设置了@task(track_started = True)选项时才会记录。
PENDING 状态实际上不是记录状态,而是任何未知任务ID的默认状态,从此示例中看到:
1 | >>> from proj.celery import app |
对于重试的任务,他的状态会变得复杂,例如重试了两次的任务,它是这样的:
1 | PENDING -> STARTED -> RETRY -> STARTED -> RETRY -> STARTED -> SUCCESS |
设计工作流
通常情况下,使用delay调用任务实现异步,但是有时候,需要将任务调用的签名传递给另一个进程或作为另一个方法的参数,celery称这种方式叫签名。
签名以一种方式包装单个任务调用的参数和其他可选参数,以便它可以传递给函数,甚至可以进行序列化和发送。
下面为任务创建一个签名,并传递参数:
1 | >>> add.signature((2, 2), countdown=10) |
也可以写成这样:
1 | >>> add.s(2, 2) |
另外,signature也可以使用Calling API(delay、apply_async )。不同的是,signature对象可能为任务指定了参数,例如add任务需要有两个参数,那么有两个参数的signature,就是完整的signature对象了:
1 | >>> s1 = add.s(2, 2) |
当然,也可以创建不完整的signature对象:
1 | >>> s2 = add.s(2) |
add任务需要两个参数,但是签名对象只赋予了它一个参数,我们可以在调用任务的时候,对任务再次进行赋值:
1 | >>> res = s2.delay(8) |
signature对象的实际用处
以下这些他们本身就是signature对象,因此,他们以多种方式组合以组成复杂的工作流:
1 | group chain chord |
Groups
group会并行调用任务,并以列表的形式返回
1 | >>> from celery import group |

传递部分参数:
1 | >>> g = group(add.s(i) for i in range(10)) |
Chains
chain会把任务链接到一起,当前一个任务完成后,会将结果传递给下一个任务继续执行:
1 | >>> from celery import chain |
或
1 | >>> # (? + 4) * 8 |
也可以简化成:
1 | >>> (add.s(4, 4) | mul.s(8))().get() |
Chords
chord是一个有回调的group:
1 | >>> from celery import chord |
如果将group和其他任务chain到一起,就会自动变成了chord了:
1 | >>> (group(add.s(i, i) for i in range(10)) | xsum.s())().get() |