参考文档:
环境:
python: 3.7
celery: 4.2.1
什么是生产者与消费者模式
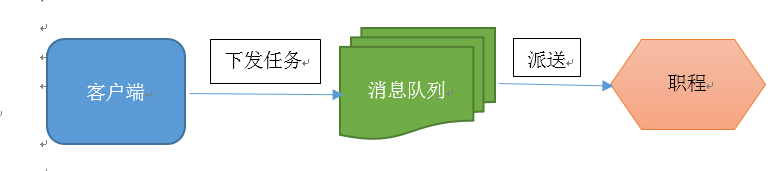
在实际的软件开发过程中,经常会碰到如下场景:某个模块负责产生数据,这些数据由另一个模块来负责处理(此处的模块是广义的,可以是类、函数、线程、进程等)。产生数据的模块,就形象地称为生产者;而处理数据的模块,就称为消费者。
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过消息队列(缓冲区)来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给消息队列,消费者不找生产者要数据,而是直接从消息队列里取,消息队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。这个消息队列就是用来给生产者和消费者解耦的。
如图所示:

通过这样的模式,可以解决并发的问题,而celery就有效的利用这样一个模式的框架。
什么是celery
Celery 是一个基于python开发的分布式异步消息任务队列,通过它可以轻松的实现任务的异步处理。
任务队列的输入是称为任务的工作单元,专用工作进程不断监视任务队列以执行新工作。
celery通过消息进行通信,通常使用broker(消息队列)将客户端与worker解藕。客户端向broker中添加消息,然后broker将消息传递给worker。
celery可以有多个worker和broker,这实现了高可用和水平扩展。
如图所示:
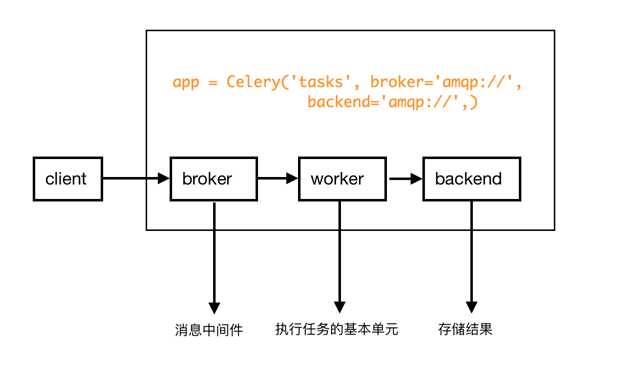
celery的架构主要由三部分组成:
消息队列(消息中间件):celery本身无法接收或发送消息,这个时候就需要一个中间人帮celery来完成。这个中间人就是消息中间件,也就是上面说的broker。broker包括:RabbitMQ,Redis,MongoDB等
worker:执行任务的基本单元。一个celery可以有多个worker。worker运行在分布式的各个系统中。
backend:用来存储任务的执行结果。celery支持很多种存储结构的方法:Redis,MongoDB,Django ORM,AMQP等
如图所示:
快速入门
celery的架构分为三部分:broker,worker,backend
那么首先,需要选择一个适合我们的broker。这里会介绍rabbitMQ和redis作为broker的用法
rabbitMQ
安装
1
brew install rabbitmq
安装后的地址在:
/usr/local/Cellar/将
/usr/local/Cellar/rabbitmq/3.7.8/sbin添加到.bash_profile中,便于使用1
export PATH=$PATH:/usr/local/Cellar/rabbitmq/3.7.8/sbin
启动与停止
1
sudo rabbitmq-server
注意,rabbimq停止的时候不要用kill命令,要用下面这个:
1
sudo rabbitmqctl stop
redis
安装
1
pip3 install -U "celery[redis]"
启动与停止
1
redis-server
1
redis-cli shutdown
下面,我们来安装celery
1 | pip3 install celery |
实现一个celery架构的第一步,就是需要一个celery实例。通常这个实例叫app,并且这个实例将作为一切你想在celery中做的事的入口。所以,必须保证app所在的module可以让任意一个文件导入。
这里我们做一个简单的示例,把所有东西都写在一个module(tasks.py)中
1 | from celery import Celery |
Celery的第一个参数“tasks”是当前module的名称。只有当“name == ‘main’”的时候才能自动生成名称
第二个参数“broker”,指定了使用的消息中间件的url,这里使用的是rabbitmq
使用“@app.task”装饰的“add”,将作为任务放到任务队列中
运行一下,看看效果
1 | celery -A tasks worker --loglevel=info |
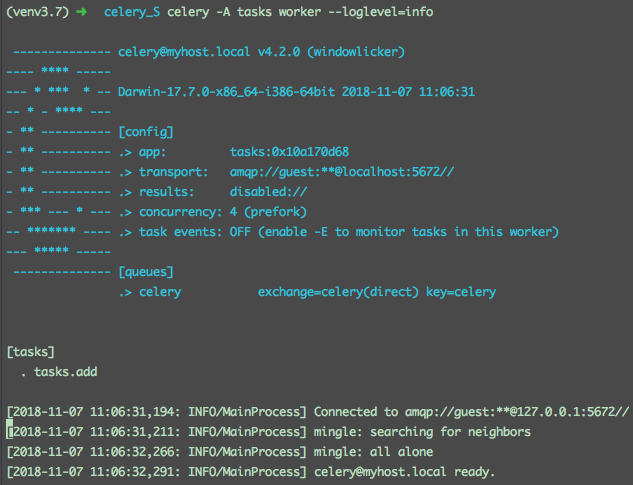
celery启动后,我们需要向celery中添加任务
1 | >>> from tasks import add |
delay()是apply_async()的一种快捷使用方式,用来更好的控制任务的执行
控制台打印了如下信息:

我们可以看到,add任务已经被worker处理。
调用一个任务,将返回一个AsyncResult实例。这个实例可以用来检查任务的状态,从而等待任务完成并获取其返回值
这里我们没有设置backend,所以在通过AsyncResult实例检查任务状态时,会报错AttributeError: 'DisabledBackend' object has no attribute '_get_task_meta_for'
上面提到的会报错,原因是没有一个backend可以用来存储任务的状态及结果,因此,我们在上面的tasks.py中,添加backend参数
1 | from celery import Celery |
重新启动celery,再次调用任务
1 | >>> from tasks import add |
这时我们会发现控制台打印了和上面一样的内容
同时,我们通过result(这是一个AsyncResult实例)检查任务的状态
1 | >>> result.ready() |
结果为True,证明已经执行结束,此时,我们查看结果
1 | >>> result.get() |
这里我们用了两个方式去获取结果,他们的区别在于get()在获取到结果的时候,同时释放了资源,而result却没有。backend在存储和传输结果的时候,会占用资源,因此推荐使用get()。
我们的backend使用了redis来存储,那么我们去redis中看一看结果

这样一个celery的简单入门就结束啦~~~